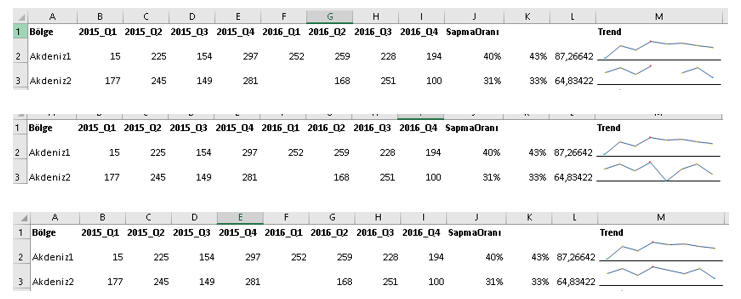
Sparkline
Excelin 2010 versiyonuyla hayatımıza giren Sparkline'lar hücre içi grafikler olarak adlandırabileceğimiz harika araçlardır.
Şimdi diyelim ki aşağıdaki gibi bir listeniz var. Bölgelerin çeyrek satışlarını gösteren bu liste tek bakışta bize hızlı bir bilgi vermiyor. Bildiğiniz gibi tek bakışta daha hızlı algılama sağlayan araçlar grafikler gibi görsel araçlardır. Liste halindeki data ise daha detaylı incelemeler için yararlıdır. Şimdi elimizde 10 tane bölge varken 10 ayrı grafik yapmak hem oldukça zahmetli olacaktır hem de ekranda çok yer kaplayacaktır.
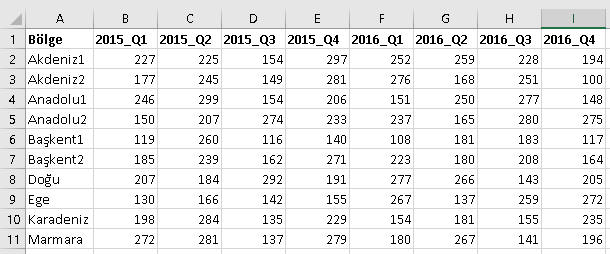
10 grafik yerine sadece 4 tane bile oldukça yer kapladı.
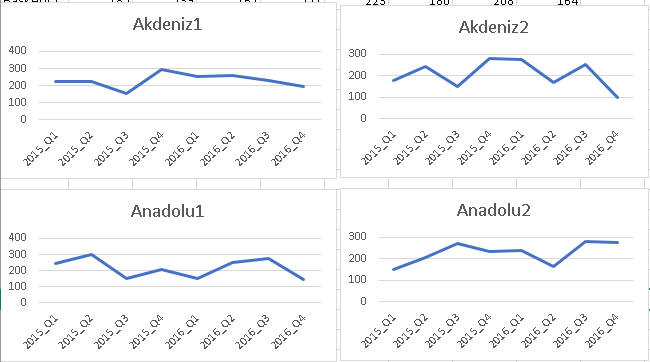
Alternatif olarak tüm bölgeleri tek grafikte gösterebilirsiniz ama 10 bölge için çok da şık görünmüyor, değil mi?
İşte böyle durumlar için Sparkline kullanabiliriz.

Üstelik bu mini grafikler içine en yüksek noktayı, en düşük noktayı gösteren işaretler koyabilir, bunların renklendirmesini farklılaştırabilirsiniz.
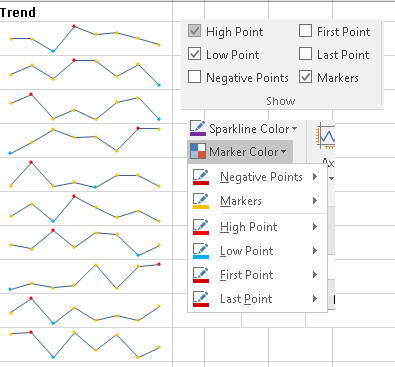
Grafiğin türünü çizgiden çubuklara da dönüştürebilirsiniz.
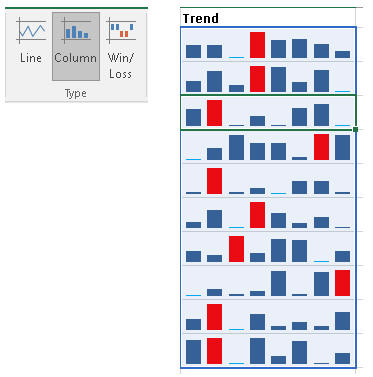
Dalgalanmaların(Genel trendden sapan noktaların) tespiti
Tabi gerek çizgisel formda gerek çubuksal formda olsun rakamlar birbirine çok yakın olsa bile dalgalanmalar(sapmalar) çok yüsek görünebilmektedir, ki bu bazen yanıltıcı olabilir. İşte böyle bir durumda Sparkline'ı varsayılan şekliyle kullanmak size çok yarar sağlamaz. Çünkü Excel, varsayılan olarak data grubunda bulunan en küçük değeri y ekseninin minimum değeri olarak alır. Halbuki amacımız dönemsel dalgalanmayı tespit etmek ise, minimum değer olarak 0 seçmeliyiz.(Başka durumlarda minimum değer olarak başka değerler seçilebilir)
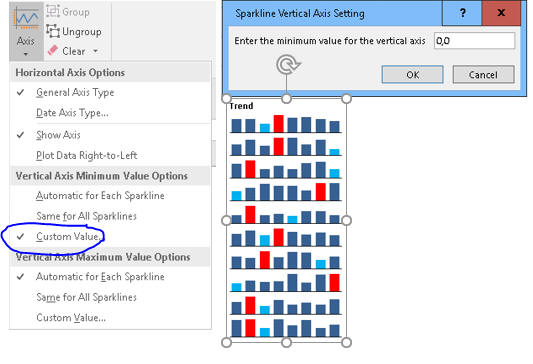
Gördüğünüz(üstteki resimde sağ alttaki Trend bölgesi) gibi şimdi daha anlamlı oldu ve mesela ben ikinci bölgenin son ayı dışında bir dalgalanma gömüyorum, ki bu bile tam bir dalgalanma sayılmaz. Bunun yerine mesela Akdeniz1 bölgesinin ilk ayını 15 yaptığımızda sapmayı çok net şekilde görebiliyoruz.

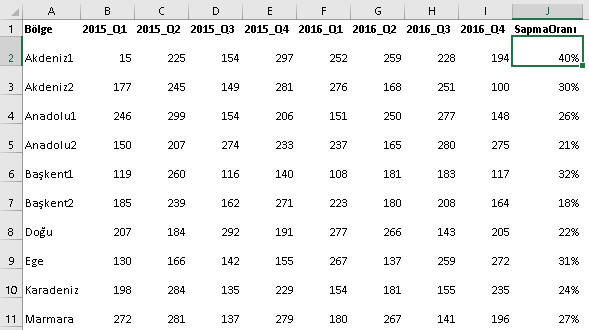
Tabi elinizde 10-15 adetlik bölge listesi değil de 1000 adetlik bir şube listesi varsa bunu sparkline'dan tespit etmek yerine, bir formül yazmak ve filtre uygulamak daha akıllıca olacaktır. Ben bir data kümesindeki sapma oranını tespit etmek için aşağıdaki formülü kullanıyorum. Genelde %30un üzerini de sapan küme olarak değerlendiriyorum, amacım doğrultusunda bazen bu %30u aşağı bazen de yukarı çekiyorum. J2'deki formülüm şöyle.
=STDEV.P(B2:I2)/AVERAGE(B2:I2)
Boş değerler
Veri listesindeki boş değerlerin nasıl gösterileceğini de aşağıdaki gibi belirleyebilirsiniz.
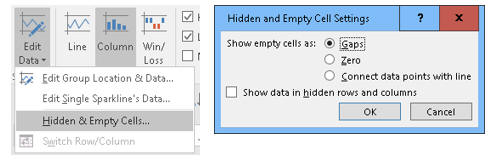
Aşağıda boş hücrelerin sırasyıla Boşluk, Sıfır ve komşuların birleştirimi şeklinde gösterimi seçildiğinde sparkline'ın nasıl görüneceği bulunuyor.